
As the size of a knowledge base grows, performance becomes more problematic. The inference engines we have looked at so far use a simple pattern matching algorithm to find the rules to fire. Various indexing schemes can be used to speed up that pattern matching process.
The indexing problem is different for forward and backward chaining systems. Backward chaining systems need to be accessed by the goal pattern in the right hand side of the rule. Forward chaining systems need to be indexed by the more complex patterns on the left hand side. Backward chaining issues will be discussed briefly in this chapter, followed by more in depth treatment of a simplified Rete match algorithm for the Foops forward chaining system.
For performance in backward chaining systems, the rules are indexed by goal patterns on the right hand side. In particular, if the goal is to find a value for a given attribute, then the rules should be indexed by the attribute set in the RHS of the rule. This happens automatically for the pure Prolog rules in the bird identification program since the attributes are Prolog predicate names which are generally accessed through hashing algorithms. The indices, if desired, must be built into the backward chaining engine used in Clam. Some Prologs provide automatic indexing on the first argument of a predicate. This feature could be used to provide the required performance.
Given indexing by the first argument, the rules in Clam would be represented:
rule(Attribute, Val, CF, Name, LHS).
This way, a search for rules providing values for a given attribute would quickly find the appropriate rules.
Without this, each rule could be represented with a functor based on the goal pattern and accessed using the univ (=..) predicate rather than the pattern matching currently used in Clam. The predicates which initially read the rules can store them using this scheme. For example, the internal format of the Clam rules would be:
Attribute(Val, CF, Name, LHS).
In particular, some rules from the car diagnostic system would be:
problem(battery,
100, 'rule 1',
[av(turn_over, no), av(battery_bad, yes)]).
problem(flooded,
80, 'rule 4',
[av(turn_over, yes), av(smell_gas, yes)]).
battery_bad(yes, 50, 'rule 3', [av(radio_weak, yes)]).
When the inference is looking for rules to establish values for an attribute - value pattern, av(A, V), the following code would be used:
Rule =.. [A, V, CF, ID, LHS],
call(Rule),
...
This structure would allow Clam to take advantage of the hashing algorithms built into Prolog for accessing predicates.
OPS5 and some high-end expert system shells use the Rete match algorithm to optimize performance. It is an indexing scheme which allows for rapid matching of changes in working memory with the rules. Previous match information is saved on each cycle, so the system avoids redundant calculations. We will implement a simplified version of the Rete algorithm for Foops.
The Rete algorithm is designed for matching left hand side rule patterns against working storage elements. Let's look at two similar rules from the room placement expert system.
rule f3#
[couch - C with [position-wall/W],
wall - W with [opposite-OW],
tv - TV with [position-none, place_on-floor]]
==>
[update(tv - TV with [position-wall/OW])].
rule f4#
[couch - C with [position-wall/W],
wall - W with [opposite-OW],
tv - TV with [position-none, place_on-table],
end_table - T with [position-none]]
==>
[update(end_table - T with [position-wall/OW]),
update(tv - TV with [position-end_table/T])].
First let's define some terms. Each LHS is composed of one or more frame patterns. An example of a frame pattern is:
tv-TV with [position-none, place_on-table]
The frame pattern will be the basic unit of indexing in the simplified Rete match algorithm. In a full implementation, indexing is carried down to the individual attribute-value pairs within the frame pattern, such as place_on-table.
The match algorithm used in the first implementation of Foops takes every rule and compares it to all the frame instances on each cycle. In particular, both of the example rules above would be compared against working storage on each cycle. Not only is redundant matching being done on each cycle, within each cycle the same frame patterns are being matched twice, once for each rule. Since working memory generally has few changes on each cycle, and since many of the rules have redundant patterns, this approach is very inefficient.
With the Rete algorithm, the status of the match information from one cycle is remembered for the next. The indexing allows the algorithm to update only that match information which is changed due to working memory changes.
The rules are compiled into a network structure where the nodes correspond to the frame patterns in the LHS of the rules. There are three basic types of node which serve as: the entry to the network; the internals of the network; and the exit from the network. These are called root nodes, two-input nodes, and rule nodes respectively.
Figure 8.1. The nodes of the Rete network for two sample rules
The network has links which run from single frame patterns in the root nodes, through the two-input nodes, to full LHS patterns in the rule nodes. Figure 8.1 shows the nodes and links generated from the two sample rules.
The root nodes serve as entry points to the Rete network. They are the simplest patterns recognized by the network, in this case the frame patterns that appear in the various rules. A frame pattern only appears once in a root node even if it is referenced in multiple rules. Each root node has pointers to two-input nodes which are used to combine the patterns into full LHS patterns.
Two-input nodes represent partially completed LHS patterns. The left input has a pattern which has one or more frame patterns as they appear in one or more rules. The right input has a single frame pattern, which when appended to the left input pattern completes more of a full LHS pattern. The two-input node is linked to other two-input or rule nodes whose left input matches the larger pattern.
The rule nodes are the exit points of the Rete network. They have full LHS patterns and RHS patterns.
Associated with each two-input node, are copies of working storage elements which have already matched either side of the node. These are called the left and right memories of the node. In effect, this means working memory is stored in the network itself.
Whenever a frame instance is added, deleted, or updated it is converted to a "token". A token is formed by comparing the frame instance to the root patterns. A root pattern which is unified with the frame instance is a token. The token has an additional element which indicates whether it is to be added to or deleted from the network.
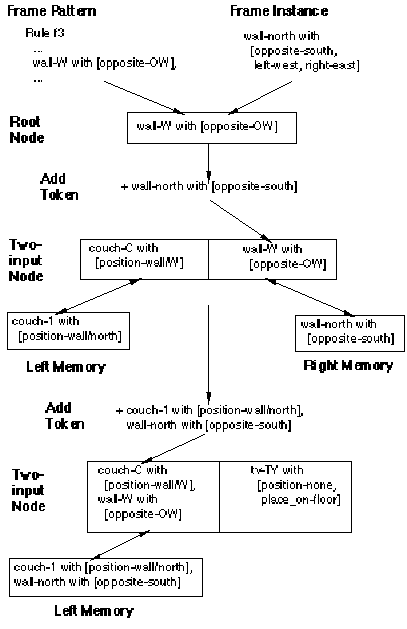
Figure 8.2. The relationship between frame patterns, instances, tokens, and nodes
The token is sent from the root node to its successor nodes. If the token matches a left or right pattern of a two-input successor node, it is added (or deleted) from the the appropriate memory for that node. The token is then combined with each token from the memory on the other side (right or left) and compared with the pattern formed by combining the left and right patterns of the two input node. If there is a match, the new combined token is sent to the successor nodes. This process continues until either a rule is instantiated or there are no more matches.
Figure 8.2 shows the relationships between rules, frame patterns, frame instances, nodes, and tokens. It shows the top portion of the network as shown in Figure 8.1. It assumes that couch-1 with [position-wall/north] already exists in the left memory of two-input node #1. Then the frame instance wall-north with [opposite-south, left-west, right-east] is added, causing the generation of the token wall-north with [opposite-south]. The token updates the right memory of node #1 as shown, and causes a new token to be generated which is sent to node #2, causing an update to its left memory.
Lets trace what happens in the network during selected phases of a run of the room configuration system.
First the walls are placed during initialization. There are four wall frame instances asserted which define opposites and are therefor recognized by the portion of the system we are looking at. They are used to build add-tokens which are sent to the network.
wall-north with [opposite-south].
wall-south with [opposite-north].
wall-east with [opposite-west].
wall-west with [opposite-east].
Each of these tokens matches the following root pattern, binding OW to the various directions:
wall-W with [opposite-OW].
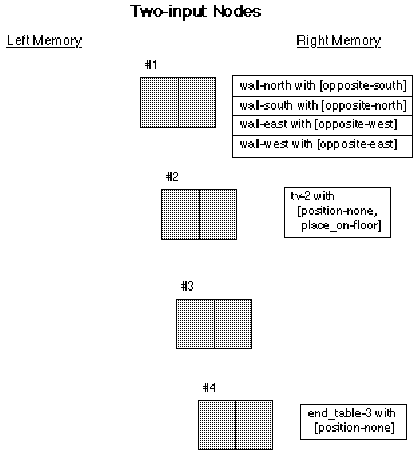
Figure 8.3. The sample network after initialization
Therefore, each token is passed on to the right side of two-input node #1 as indicated by the list of links associated with that root pattern. Each of these terms is stored in the right memory of node #1. Since there is nothing in the left memory of node #1, network processing stops until the next input is received.
Next, the furniture is initialized, with the couch, tv, and end_table placed with position-none. They will be internally numbered 1, 2, and 3. Since the root pattern for couch in the segment we are looking at has a position-wall/W, the couch does not show up in it at this time. However, node #2 and node #4 have their right memories updated respectively with the tokens:
tv-2 with [position-none, place_on-floor].
end_table-3 with [position-none].
At this point the system looks like figure 8.3. The shaded boxes correspond to the two-input nodes of figure 8.1.
After initialization, the system starts to fire rules. One of the early rules in the system will lead to the placing of the couch against a wall, for example the north wall. This update will cause the removal of the token couch-1 with [position-none] from parts of the network not shown in the diagrams, and the addition of the token couch-1 with [position-wall/north] to the left memory of node #1 as shown in figure 8.4. This causes a cascading update of various left memories as shown in the rest of figure 8.4 and described below.
Node #1 now has both left and right memories filled in, so the system tries to combine the one new memory term with the four right memory terms. There is one successful combination with the wall-north token, so a new token is built from the two and passed to the two successor nodes of node #1. The new token is:
[couch-1 with [position-wall/north],
wall-north with [opposite-south] ]
This token is stored in the left memories of both successors, node #2 and node #3. There is no right memory in node #3, so nothing more happens there, but there is right memory in node #2 which does match the input token. Therefor a new token is constructed and sent to the successor of node #2. The new token is:
[couch-1 with [position-wall/north],
wall-north with [opposite-south],
tv-2 with [position-none, place_on-floor] ]
The token is sent to the successor which is rule #f3. The token is the binding of the left side of the rule, and leads to variable bindings on the right side of the rule. This is a full instantiation of the rule and is added to the conflict set. When the rule is fired, the action on the right side causes the position of the tv to be updated.
update ( tv-2 with [position-wall/south] )
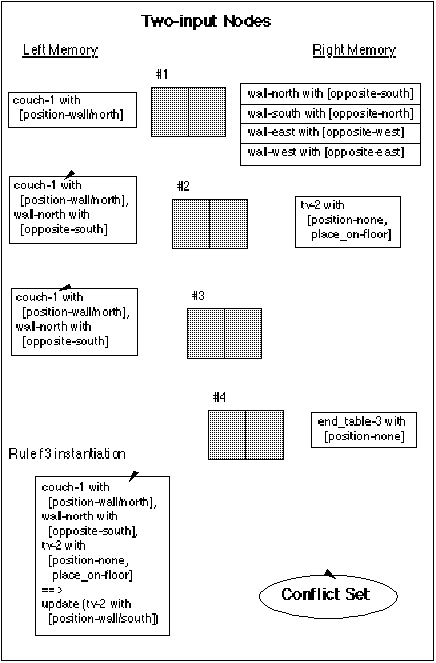
Figure 8.4. The cascading effect of positioning the couch
This update causes two tokens to be sent through the network. One is a delete token for tv-2 with [position-none], and the other is an add token for tv-2 with [position-wall/south]. The delete causes the removal of the token from the right memory of node#2. The add would not match any patterns in this segment of the network.
The Rete network provides a number of performance improvements over a simple matching of rules to working memory:
• The root nodes act as indices into the network. Only those nodes which are affected by an update to working memory are processed.
• The patterns which have been successfully matched are saved in the node left and right memories. They do not have to be reprocessed.
• When rules share common sequences of patterns, that information is stored only once in the network, meaning it only has to be processed once.
• The output of the network is full rule instantiations. Once an instantiation is removed from the conflict set (due to a rule firing) it will not reappear on the conflict set, thus preventing multiple firings of the rule.
Next, let's look at the code to build a Rete pattern matcher. First we will look at the data structures used to define the Rete network, then the pattern matcher which propagates tokens through the network, and finally the rule compiler which builds the network from the rules.
The roots of the network are based on the frame patterns from the rules. The root nodes are represented as:
root(NID, Pattern, NextList).
NID is a generated identification for the node, Pattern is the frame pattern, and NextList is the list of succesor nodes which use the Pattern. NextList serves as the pointers connecting the network together.
For example:
root(2, wall-W with [opposite-OW], [1-r]).
The two-input nodes of the network have terms representing the patterns which are matched from the left and right inputs to the node. Together they form the template which determines if particular tokens will be successfully combined into rule instantiations. The format of this structure is:
bi(NID, LeftPattern, RightPattern, NextList).
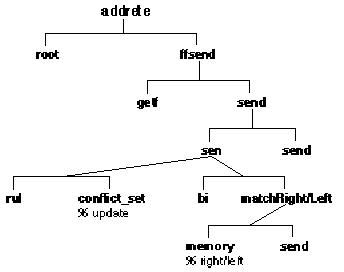
Figure 8.5 Major predicates which propagate a token through the network
NID again is an identification. LeftPattern is the list of frame patterns that have been matched in nodes previous to this one. RightPattern is the new frame pattern which will be appended to the LeftPattern. NextList contains a list of successor nodes.
For example:
bi(1, [couch-C
with [position-wall/W]],
[wall-W with [opposite-OW],
[2-l, 3-l]).
bi(2, [couch-C
with [position-wall/W],
wall-W with [opposite-OW]],
[tv-TV with [position-none, place_on-floor]],
[rule(f3)]).
The end of the network is rules. The rules are stored as:
rul(N, LHS, RHS).
N is the identification of the rule. LHS is the list of frame patterns which represent the full left hand side of the rule. RHS is the actions to be taken when the rule is instantiated.
Tokens are generated from the updates to frame instances. There are only two update predicates for the network, addrete which adds tokens, and delrete which deletes them. Both take as input the Class, Name, and TimeStamp of the frame instance. Both are called from the Foops predicates which update working memory: assert_ws, retract_ws, and update_ws. The major predicates of addrete are shown in figure 8.5.
The addrete predicate uses a simple repeat - fail loop to match the frame instance against each of the root nodes. It looks like:
addrete(Class,
Name, TimeStamp) :-
root(ID, Class-Name with ReqList, NextList),
ffsend(Class, Name, ReqList, TimeStamp, NextList),
fail.
addrete(_, _, _).
The ffsend predicate fullfills the request pattern in the root by a call to the frame system predicate, getf. This fills in the values for the pattern thus creating a token. Next, send is called with an add token.
ffsend(Class,
Name, ReqList, TimeStamp, NextList) :-
getf(Class, Name, ReqList),
send(tok(add, [(Class-Name with ReqList)/TimeStamp]), NextList),
!.
The delrete predicate is analagous, the only difference being it sends a delete token through the network.
delrete(Class,
Name, TimeStamp) :-
root(ID, Class-Name with ReqList, NextList),
delr(Class, Name, ReqList, TimeStamp),
fail.
delrete(_, _, _).
delr(Class,
Name, ReqList, TimeStamp) :-
getf(Class, Name, ReqList),
!, send(tok(del, [(Class-Name with ReqList)/TimeStamp]), NextList).
delr(Class, Name, ReqList, TimeStamp).
Predicate send passes the token to each of the successor nodes in the list:
send(_, []).
send(Token,
[Node|Rest]) :-
sen(Node, Token),
send(Token, Rest).
The real work is done by sen. It has to recognize three cases:
• The token is being sent to a rule. In this case, the rule must be added to or deleted from the conflict set.
• The token is being sent to the left side of a two-input node. In this case, the token is added to or deleted from the left memory of the node. The list is then matched against the right memory elements to see if a larger token can be built and passed through the network.
• The token is being sent to the right side of a node. In this case, the token is added to or deleted from the right memory of the node. It is then compared against the left memory elements to see if a larger token can be built and passed through the network.
In Prolog:
sen(rule-N,
tok(AD, Token)) :-
rul(N, Token, Actions),
(AD = add, add_conflict_set(N, Token, Actions);
AD = del, del_conflict_set(N, Token, Actions)),
!.
sen(Node-l,
tok(AD, Token)) :-
bi(Node, Token, Right, NextList),
(AD = add, asserta( memory(Node-l, Token) );
AD = del, retract( memory(Node-l, Token) )),
!, matchRight(Node, AD, Token, Right, NextList).
sen(Node-r,
tok(AD, Token)) :-
bi(Node, Left, Token, NextList),
(AD = add, asserta( memory(Node-r, Token) );
AD = del, retract( memory(Node-r, Token) )),
!, matchLeft(Node, AD, Token, Left, NextList).
Note how Prolog's unification automatically takes care of variable bindings between the patterns in the node memory, and the instance in the token. In sen, the instance in Token is unified with one of the right or left patterns in bi, automatically causing the opposite pattern to become instantiated as well (or else the call to bi fails and the next bi is tried). This instantiated Right or Left is then sent to matchRight or matchLeft respectively.
Both matchRight and matchLeft take the instantiated Right or Left and compare it with the tokens stored in the right or left working memory associated with that node. If unification is successful, a new token is built by appending the right or left from the memory with the original token. The new token is then passed further with another call to send.
matchRight(Node,
AD, Token, Right, NextList) :-
memory(Node-r, Right),
append(Token, Right, NewTok),
send(tok(AD, NewTok), NextList),
fail.
matchRight(_,
_, _, _, _).
matchLeft(Node,
AD, Token, Left, NextList) :-
memory(Node-l, Left),
append(Left, Token, NewTok),
send(tok(AD, NewTok), NextList),
fail.
matchLeft(_, _, _, _, _).
Another type of node which is useful for the system handles the cases where the condition on the LHS of the rule is a test such as L > R, or member(X, Y), rather than a pattern to be matched against working memory. The test nodes just perform the test and pass the tokens through if they succeed. There is no memory associated with them.
A final node to make the system more useful is one to handle negated patterns in rules. It works as a normal node, keeping instances in its memory which match the pattern in the rule, however it only passes on tokens which do not match.
The rule compiler builds the Rete network from the rules. The compiler predicates are not as straight forward as the predicates which propagate tokens through the network. This is one of the rare cases where the power of Prolog's pattern matching actually gets in the way, and code needs to be written to overcome it.
The very unification which makes the pattern matching propagation predicates easy to code gets in the way of the rule compiler. We allow variables in the rules, which behave as normal Prolog variables, but when the network is built, we need to know which rules are matching variables and which are matching atoms. For example, one rule might have the pattern wall/W and another might have wall/east. These should generate two different indices when building the network, but Prolog would not distinguish between them since they unify with each other.
In order to distinguish between the variables and atoms in the frame patterns, we must pick the pattern apart first, binding the variables to special atoms as we go. Once all of the variables have been instantiated in this fashion, the patterns can be compared.
But first, let's look at the bigger picture. Each rule is compared, frame pattern by frame pattern, against the network which has been developed from the rules previously processed. The frame patterns of the rule are sent through the network in a similar fashion to the propagation of tokens. If the frame patterns in the rule are accounted for in the network, nothing is done. If a pattern is not in the network, then the network is updated to include it.
The top level predicate for compiling rules into a Rete net, reads each rule and compiles it. The major predicates involved in compiling rules into a Rete network are shown in figure 8.6.
rete_compil
:-
rule N# LHS ==> RHS,
rete_comp(N, LHS, RHS),
fail.
rete_compil.
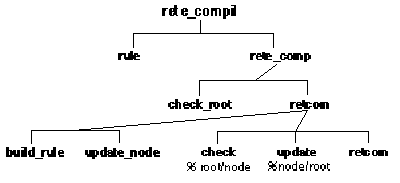
Figure 8.6 The major predicates for compiling rules into a Rete network
The next predicate, rete_comp, looks at the first frame pattern in the rule and determines if it should build a new root node or if one already exists. It then passes the information from the root node and the rest of the rule left hand side to retcom which continues traversing and/or building the network.
rete_comp(N,
[H|T], RHS) :-
term(H, Hw),
check_root(RN, Hw, HList),
retcom(root(RN), [Hw/_], HList, T, N, RHS),
!.
rete_comp(N, _, _) .
The term predicate merely checks for shorthand terms of the form Class-Name and replaces them with the full form Class-Name with []. Terms already in full form are left unchanged.
term(Class-Name, Class-Name with []).
term(Class-Name with List, Class-Name with List).
The check_root predicate determines if there is already a root node for the term, and if not creates one. It will be described in detail a little later. The third argument from check_root is the current list of nodes linked to this root.
The last goal is to call retcom, which is the main recursive predicate of the compilation process. It has six arguments, as follows:
PNID the id of the previous node
OutPat pattern from previous node
PrevList successor list from previous node
[H|T] list of remaining frame patterns in rule
N rule ID, for building the rule at the end
RHS RHS of the rule, for building the rule at the end
There are two cases recognized by retcom:
• All of the frame patterns in the rule have been compiled into the network, and all that is left is to link the full form of the rule to the network.
• The rule frame patterns processed so far match an existing two-input node, or a new one is created.
In Prolog, the first case is recognized by having the empty list as the list of remaining frame patterns. The rule is built, and update_node is called to link the previous node to the rule.
retcom(PNID,
OutPat, PrevList, [], N, RHS) :-
build_rule(OutPat, PrevList, N, RHS),
update_node(PNID, PrevList, rule-N),
!.
In the second case, the frame pattern being worked on (H) is first checked to see if it has a root node. Then the network is checked to see if a two-input node exists whose left input pattern matches the rule patterns processed so far (PrevNode). Either node might have been found or added, and then linked to the rest of the network.
retcom(PNID,
PrevNode, PrevList, [H|T], N, RHS) :-
term(H, Hw),
check_root(RN, Hw, HList),
check_node(PrevNode, PrevList, [Hw/_], HList, NID, OutPat, NList),
update_node(PNID, PrevList, NID-l),
update_root(RN, HList, NID-r),
!,
retcom(NID, OutPat, NList, T, N, RHS).
Building rules is simply accomplished by writing a new rule structure:
build_rule(OutPat,
PrevList, N, RHS) :-
assertz( rul(N, OutPat, RHS) ).
The check_root predicate is the first one that must deal with the pattern matching problem mentioned earlier. It covers three cases:
• There is no existing root which matches the term using Prolog's pattern matching. In this case a new root is added.
• There is an existing root which matches the term, atom for atom, variable for variable. In this case no new root is needed.
• There is no precise match and a new root is created.
In Prolog:
check_root(NID,
Pattern, []) :-
not(root(_, Pattern, _)),
gen_nid(NID),
assertz( root(NID, Pattern, []) ), !.
check_root(N,
Pattern, List) :-
asserta(temp(Pattern)),
retract(temp(T1)),
root(N, Pattern, List),
root(N, T2, _),
comp_devar(T1, T2), !.
check_root(NID,
Pattern, []) :-
gen_nid(NID),
assertz( root(NID, Pattern, []) ).
The first clause is straight forward. The gen_nid predicate is used to generate unique numbers for identifying nodes in the Rete network.
The second clause is the difficult one. The first problem is to make a copy of Pattern which Prolog will not unify with the original term. The easiest way is to assert the term and then retract it using a different variable name, as the first two goals of the second clause do. We now have both Pattern and T1 as identical terms, but Prolog doesn't know they are the same and will not bind the variables in one when they are bound in the other.
We can now use Pattern to find the root which matches it, using Prolog's match. Again, not wishing to unify the variables, we call the root again using just the root identification. This gives us T2, the exact pattern in the root before unification with Pattern.
Now we have T1 and T2, two terms which we know will unify in Prolog. The problem is to see if they are also identical in their placement of variables. For this we call comp_devar which compares two terms after unifying all of the variables with generated strings.
A very similar procedure is used for check_node. It is a little more complex in that it needs to build and return the tokens that are the two inputs to a node. The arguments to check_node are:
PNode token list from previous node
PList list of successor nodes from previous node
H new token being added
HList successor nodes from root for token H
NID returned ID of the node
OutPat returned tokenlist from the node
NList returned list of successor nodes from the node
The clauses for check_node are:
check_node(PNode,
PList, H, HList, NID, OutPat, []) :-
not (bi(_, PNode, H, _)),
append(PNode, H, OutPat),
gen_nid(NID),
assertz( bi(NID, PNode, H, []) ),
!.
check_node(PNode,
PList, H, HList, NID, OutPat, NList) :-
append(PNode, H, OutPat),
asserta(temp(OutPat)),
retract(temp(Tot1)),
bi(NID, PNode, H, NList),
bi(NID, T2, T3, _),
append(T2, T3, Tot2),
comp_devar(Tot1, Tot2),
check_node(PNode,
PList, H, HList, NID, OutPat, []) :-
append(PNode, H, OutPat),
gen_nid(NID),
assertz( bi(NID, PNode, H, []) ).
The update predicates check to see if the new node is on the list of links from the old node. If so, nothing is done. Otherwise a new link is added by putting the new node id on the list.
update_root(RN,
HList, NID) :-
member(NID, HList), !.
update_root(RN,
HList, NID) :-
retract( root(RN, H, HList) ),
asserta( root(RN, H, [NID|HList]) ).
update_node(root(RN),
HList, NID) :-
update_root(RN, HList, NID), !.
update_node(X,
PrevList, NID) :-
member(NID, PrevList), !.
update_node(PNID,
PrevList, NID) :-
retract( bi(PNID, L, R, _) ),
asserta( bi(PNID, L, R, [NID|PrevList]) ).
The comp_devar predicate takes each term it is comparing, and binds all the variables to generated terms.
comp_devar(T1,
T2) :-
del_variables(T1),
del_variables(T2),
T1=T2.
The del_variables predicate is used to bind the variables. The function which generates atoms to replace the variables is initialized the same way each time it is called, so if T1 and T2 have the same pattern of variables, they will be replaced with the same generated atoms and the terms will be identical.
del_variables(T)
:-
init_vargen,
de_vari(T).
The basic strategy is to recognize the various types of structures and break them into smaller components. When a component is identified as a variable, it is unified with a generated atom.
First, de_vari looks at the case where the terms are lists. This is used for comparing token lists in check_node. It is a standard recursive predicate which removes the variables from the head of the list, and recursively calls itself with the tail. Note that unification will cause all occurances of a variable in the head of the list to be bound to the same generated atom. The third clause covers the case where the term was not a list.
de_vari([]).
de_vari([H|T])
:-
de_var(H),
de_vari(T).
de_vari(X) :- de_var(X).
The first clause of de_var removes the time stamps from consideration. The next two clauses recognize the full frame pattern structure, and the attribute-value pair structure respectively.
de_var(X/_) :- de_var(X).
de_var(X-Y
with List) :-
de_v(X-Y),
de_vl(List), !.
de_var(X-Y)
:-
de_v(X-Y), !.
The next predicates continue to break the structures apart until finally d_v is given an elementary term as an argument. If the term is a variable, an atom is generated to replace it. Otherwise the term is left alone. Due to Prolog's unification, once one instance of a variable is unified to a generated term, all other instances of that variable are automatically unified to the same generated term. Thus, the generated atoms follow the same pattern as the variables in the full term.
de_vl([]).
de_vl([H|T])
:-
de_v(H),
de_vl(T).
de_v(X-Y)
:-
d_v(X),
d_v(Y).
d_v(V) :-
var(V),
var_gen(V), !.
d_v(_).
The next two predicates are used to generate the variable replacements. They are of the form '#VAR_N', where N is a generated integer. In this case two built-in predicates of AAIS Prolog are used to convert the integer to a string and concatenate it to the rest of the form of the variable. The same effect could be achieved with the standard built-in, name, and a list of ASCII characters representing the string.
init_vargen
:-
abolish(varg, 1),
asserta(varg(1)).
var_gen(V)
:-
retract(varg(N)),
NN is N+1,
asserta(varg(NN)),
int2string(N, NS),
stringconcat("#VAR_", NS, X),
name(V, X).
The system only handles simple rules so far, and does not take into account either negations or terms which are tests, such as comparing variables or other Prolog predicate calls.
Nodes to cover tests are easily added. They are very similar to the normal two-input nodes, but do not have memory associated with them. The left side is a token list just as in the two-input nodes. The right side has the test pattern. If a token passes the test, a new token with the test added is passed through the network.
The negated patterns store a count with each pattern in the left memory. That count reflects the number of right memory terms which match the left memory term. Only when the count is zero, is a token allowed to pass through the node.
Only a few changes have to be to Foops to incorporate the Rete network developed here.
A compile command is added to the main menu that builds the Rete network. It is called after the load command.
The commands to update working memory are modified to propagate tokens through the Rete network. This means calls to addrete and delrete as appropriate.
The refraction logic, which ensured the same instantiation would not be fired twice, is removed since it is no longer necessary.
The predicate which builds the conflict set is removed since the conflict set is maintained by the predicates which process the network. The predicates which sort the conflict set are still used to select a rule to fire.
There are a number of design tradeoffs made in this version. The first is the classic space versus speed tradeoff. At each Rete memory, a full copy of each token is saved. This allows it to be retrieved and matched quickly during execution. Much space could be saved by only storing pointers to the working memory elements. These would have to be retrieved and the token reconstructed when needed.
The other tradeoff is with the flexibility of the frame system. With the frames in the original Foops, the frame patterns in the rules could take advantage of inheritance and general classes as in the rules which determined a need for electrical plugs in a room. Since Rete-Foops instantiates the patterns before propagating tokens through the network, this does not work. This feature could be incorporated but would add to the burden and complexity of maintaining the network.
8.1 - Implement nodes which support rules which have tests such as X > Y, and negated frame patterns.
8.2 - The implementation described in this chapter makes heavy use of memory by storing the full tokens in left and right memories. Build a new system in which space is saved by storing a single copy of the token and having pointers to it in left and right memory. The stored tokens just match single frame patterns. The complex tokens in the middle of the network contain lists of pointers to the simple tokens.
8.3 - Experiment with various size systems to see the performance gains of the Rete version of Foops.
8.4 - Figure out a way to allow Rete-Foops to use inheritance in frame patterns. That is, fix it so the rule which finds electric plugs works.
8.5 - Build an indexed version of Clam and make performance experiments with it.
Copyright ©1989,2000 Amzi! inc. All Rights Reserved.